LeetCode算法题解答记录,不常更新,随缘维护。
PS:经过几次更新,并非按照LeetCode上的顺序进行解答记录的,各位看官自行摘取需要的内容进行阅读。
1 两数之和
记得面试时是被问到过这个题的,但当时被前面的面试题搞的有些发懵,理解错了“不能重复利用这个数组中同样的元素”这句话的含义,实在惭愧,再看到这道题时一时感慨万千。
问题描述
给定一个整数数组 nums 和一个目标值 target ,请你在该数组中找出和为目标值的那 两个整数 ,并返回他们的 数组下标 。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
解答过程
首先分析下问题:
- 参数:数组 nums 是一个无序整数数组,元素可重复;target 是一个整数
- 需求:target是数组中两个元素的和;数组中必有也只有两个元素能满足条件;不能重复利用两个数组中同样的元素
- 结果:满足需求的两个元素的下标
- 疑问:未能理解 不能重复利用两个数组中同样的元素 这个要求
- 思路:两个循环嵌套找出所需元素,返回下标
虽然下面的两次代码都通过了测试,但是没有满足 不能重复利用两个数组中同样的元素 这个条件。
带着疑问我们看了标准答案,发现也是正确答案,不过是占用资源最多的解法,最优解思路确实很妙。
1 | /** |
1 | /** |
标准答案
暴力法
1 | public int[] twoSum(int[] nums, int target) { |
两遍哈希表
该方法利用了HashMap#containsKey函数,大幅提升了执行效率。
资源占用:
执行用时 : 12 ms, 在Two Sum的Java提交中击败了68.76% 的用户
内存消耗 : 38.7 MB, 在Two Sum的Java提交中击败了0.99% 的用户
1 | public int[] twoSum(int[] nums, int target) { |
一遍哈希表
该方法也是利用了HashMap实现,但是原理与两遍哈希表的解法不同,通过将遍历过的元素和元素下标缓存起来,在下个循环判断缓存中是否有本循环元素相加等于目标值,有则返回。妙!
资源占用:
执行用时 : 11 ms, 在Two Sum的Java提交中击败了73.97% 的用户
内存消耗 : 41.2 MB, 在Two Sum的Java提交中击败了0.99% 的用户
1 | public int[] twoSum(int[] nums, int target) { |
7 整数反转
问题描述
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
注意:
假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。
解答过程
首先分析下问题:
- 参数:有符号整数
- 需求:将数字进行反转
- 结果:返回反转后的整数
- 思路:
- 将整数转化为字符串,取出负数符号
- 循环字符重新排列
- 将负数符号和重新排列后的字符进行组合
- 将组合后的字符串转化为整数
- 返回整数
1 | /** |
标准答案
弹出和推入数字 & 溢出前进行检查
思路
我们可以一次构建反转整数的一位数字。在这样做的时候,我们可以预先检查向原整数附加另一位数字是否会导致溢出。
算法
请原谅我才疏学浅并没有看懂详解。附上链接:整数反转-题解
1 | class Solution { |
9 回文数
问题描述
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
进阶:你能不将整数转为字符串来解决这个问题吗?
示例1:
1 | 输入: 121 |
示例2:
1 | 输入: -121 |
问题分析
- 参数:整数,有符号
- 需求:判断是否是回文数
- 结果:返回结果
- 思路-1:
- 将整数转化为字符串
- 循环字符进行倒序排列,得到倒序字符串
- 比较参数字符串和倒序后的字符串是否相同
- 返回比较结果
我的答案
1 | /** |
官方题解
1 | public class Solution { |
为了更好的理解,我执行了下面的代码进行分析:
1 | class Test { |
输出结果:
1 | ------------------ |
13 罗马数字转整数
问题描述
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
| 字符 | 数值 |
|---|---|
| I | 1 |
| V | 5 |
| X | 10 |
| L | 50 |
| C | 100 |
| D | 500 |
| M | 1000 |
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
- I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
- X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
- C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例:
| 输入 | 输出 |
|---|---|
| III | 3 |
| IV | 4 |
| IX | 9 |
| LVIII | 58 |
| MCMXCIV | 1994 |
问题分析
刚看到这个问题时感觉比较棘手,实际分析后发现并没有那么复杂,难的是算法最优解。
- 字符和数值是一对一的关系
- 有6种特殊字符表示其他的数值
- 各个字符对应的数值相加,可以得到最终值
我的答案
答案一
思路:
- 首先要建立一个字符和数值的对应表,特殊字符和数值对应表
- 遍历字符串,先取两个一组的字符判断是否是特殊字符,不是的话取单个字符对应的数值
- 对所有的数值进行累加,得到最终值
- 返回最终值
1 | /** |
答案二
上面的代码提交后虽然通过了,但是代码看起来着实不太优雅,对效率和资源占用不太满意,随之做出了下面的修改
1 | /** |
14 最长公共前缀
这个问题给我的启发很大,分治和问题变体部分扩展了我解决某些问题的思路,应着重看下。
问题描述
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串””。
说明:所有输入只包含小写字母a-z。
我的解答
根据最小长度的元素,使用二分查找法截取元素字符,再拿截取的字符串去遍历数组。
1 | /** |
提交后,发现执行用时有些高,想了下,我的解法在参数数组越长执行用时可能就越长。所以在解答该题时,越少遍历数组效率越高。
不过看了下官方题解,发现二分查找也是其中的一个解法。
官方题解
官方给出了四种解法,下面依次来看。
这里只给出解题思路,具体实现代码可在官方题解找到。
水平扫描法
随机取一个元素,遍历数组元素,将其取出的元素依次从尾部减去一个字符,与其他数组元素进行比较。
最坏的情况下,需要进行((取出的元素字符数 - 1) * (数组长度 - 1))次比较.
水平扫描
随机取一个元素,从前往后枚举这个元素字符串的每一列,先比较每个字符串相同列上的字符(即不同字符串相同下标的字符)然后再进行对下一列的比较。
分治
使用分治技巧,将原问题分成两个子问题(left,right),再将每个子问题分成两个子问题,直到不能分出子问题。在子问题中获取公共前缀,从头到尾挨个比较left和right,最终得到原问题的解。
懒得画图了,凑合看吧~~闪~~
过程:
原问题:[“leetcode”,”leetcod”,”leetco”,”leetc”,”leet”,”lee”,”le”,”l”]
子问题:[“leetcode”,”leetcod”,”leetco”,”leetc”]和[“leet”,”lee”,”le”,”l”]
子问题:[“leetcode”,”leetcod”]、[“leetco”,”leetc”]和[“leet”,”lee”],[“le”,”l”]
子结果:”leetcod”、”leetc”和”lee”、”l”
子问题:[“leetcod”,”leetc”]和[“lee”,”l”]
子结果:”leetc”和”l”
子问题:[“leetcod”,”l”]
原问题结果=子问题结果=”l”
二分查找法
取出一个元素,将元素字符从前到后分成两部分,每次都用前一部分字符去匹配,如果不能匹配说明答案在前一部分中,能匹配说明答案在后一部分(加上前一部分),再对匹配到的这一部分执行同样的流程,最终得到公共前缀。
过程:
数组:[“leetcode”,”leetco”,”leetc”,”leet”,”lees”]
取出元素:”leetcode”
匹配区间:”leetcode”
不能匹配
匹配区间:”leet”
不能匹配
匹配区间:”le”
能匹配
匹配区间:”lee”
能匹配
得到答案->”lee”
问题变体
问题描述
给定一些字符串数组Array,我们要找到字符串S与Array中元素的最长公共前缀。这样的查询操作可能会非常频繁。
官方解答
将所有的字符(数组中所有元素的字符)存储到字典树中来优化最长公共前缀查询操作。
在字典树中,从根向下的每一个节点都代表一些元素的公共前缀。
要找到字符串S与Array中元素的最长公共前缀,需要从根开始找到一条最深的路径,满足以下条件:
- 这是所查询的字符串S的一个前缀.
- 路径上的每一个子节点都有且只有一个孩子。否则,找到的路径就不是所有字符串的公共前缀。
- 路径不包含任一元素字符串结尾代表的节点。因为最长公共前缀不可能比任意一个字符串长。
20 有效的括号
问题描述
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 注意空字符串可被认为是有效字符串。
注意:空字符串可被认为是有效字符串。
我的解答
思考了小半个小时,期间进行了几次尝试,没能想出解法。为了避免浪费太多时间,就去看了官方解答动画演示后进行了代码实现。
我好菜,2333~
1 | import java.util.* |
官方题解
我看评论中有看了题解半个小时才弄懂的,所以建议先看动画演示再细看文字解释,比较容易理解。
我上面的代码实现可能不是最好的实现,所以还是建议看下官方题解。
21 合并两个有序链表
问题描述
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
我的解答
1 | class ListNode(var `val`: Int) { |
根据上面的数据结构定义,可以看出参数和返回值都是一个链表结构,而且参数链表都是有序的。所以只要创建一个结果链表,存放两个参数链表迭代比较得出的数据就行了,关键在于控制好指针在链表中的移动。
1 | /** |
官方解答
递归
将两个链表中头部较小的值,与合并剩下的两个链表的结果进行合并。递归这个过程,直到得出最终结果。
官方的这个Java代码实现真是简洁,忍不住放了出来。但是实际开发中可不要这么写,因为改变了参数链表的内容。
1 | class Solution { |
迭代
将元素少的链表逐一插入到另一个链表中正确的位置。
这个解法字面上就能理解,不再多诉。
26 删除排序数组中的重复项
问题描述
给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
问题分析
这个问题初次看时有些看不明白,有几个“点”需要知道。
- 理解下“原地算法”。
- 不能使用额外的数组去解决问题。
- 需要删除原数组中的重复元素,但不需要考虑数组中超出新长度后面的元素。
如:输入[1,1,2]后,返回值是2,数组被修改为[1,2,2]。
我的解答
最方便的做法是创建一个数组,存放过滤后的元素,在以往的开发中经常这么做。今天看到这道题,也是第一次认真的思考了下此类题的更好的解法。
1 | /** |
官方题解
看完后才发现,我的解法就是双指针法。官方题解地址
双指针法
数组完成排序后,我们可以放置两个指针 i 和 j,其中 i 是慢指针,而 j 是快指针。只要 nums[i] = nums[j],我们就增加 j 以跳过重复项。
1 | public int removeDuplicates(int[] nums) { |
27 移除元素
此题的官方地址
问题描述
给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例1:
给定 nums = [3,2,2,3], val = 3,
函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。
你不需要考虑数组中超出新长度后面的元素。
示例2:
给定 nums = [0,1,2,2,3,0,4,2], val = 2,
函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
注意这五个元素可为任意顺序。
你不需要考虑数组中超出新长度后面的元素。
问题分析
此题和删除排序数组中的重复项这道题目很相似,都要满足原地算法,并且不能使用额外的数组去解决问题,此外,解答时不需要考虑数组中超出新长度后面的元素。
我的解答
由于刚做了上面删除排序数组中的重复项这道算法题,所以很简单的就写出了下面的答案。
解答实现了两次,解题思路一样,只是具体实现有所优化。然后才发现LeetCode提交代码的结果(执行用时和内存消耗)并不准确,所以关于这个结果大家看看就好。
解题思路:用一个指针变量I记录在数组中的位置,如果I位置的元素不需要移除将I递增,否则检查I后面是否还有不需要移除的元素,有的话将这个元素值和I位置的元素调换位置。然后递增I继续向后检查。最后I的值也就是数组的新长度。
代码实现一:
1 | /** |
代码实现二:
1 | /** |
官方题解
看完官方题解后,发现代码实现其实可以更简洁高效,惭愧~
提示:
- 尝试双指针法。
- 你是否使用“元素顺序可以更改”这一属性?
- 当要删除的元素很少时会发生什么?
双指针
1 | public int removeElement(int[] nums, int val) { |
双指针 — 当要删除的元素很少时
与上面解法的区别是,考虑到了数组包含很少的要删除的元素的情况。
1 | public int removeElement(int[] nums, int val) { |
28 实现strStr()
此题的官方地址
问题描述
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = “hello”, needle = “ll”
输出: 2
示例 2:
输入: haystack = “aaaaa”, needle = “bba”
输出: -1
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
我的解答
String.indexOf()
看到该题,就想到了Java中有 String.indexOf() 这个函数可以直接调用。现成的轮子,不用白不用~
1 | /* |
双指针
虽然有现成的轮子可以使用,但是做算法题的目的还没有达到。所以费了点功夫,写出了下面的代码。没错,也是用双指针法进行求解,谁让前面几道算法题用双指针多呢~
1 | /* |
官方题解
此题没有官方题解,还是看下Java中 String.indexOf 这个轮子的实现吧。注释部分使用Google翻译翻译了一下,就是这么贴心~
1 | /** |
35 搜索插入位置
此题的官方地址
问题描述
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
你可以假设数组中无重复元素。
示例 1:
输入: [1,3,5,6], 5
输出: 2
示例 2:
输入: [1,3,5,6], 2
输出: 1
示例 3:
输入: [1,3,5,6], 7
输出: 4
示例 4:
输入: [1,3,5,6], 0
输出: 0
我的解答
这道题非常简单,随手便写出了下面的代码(暴力法)。如果考虑到数组较大的情况,还有其他的解法:二分查找法。
1 | /* |
精选解答
二分查找法
作者:liweiwei1419
链接:点这里
来源:力扣(LeetCode)
1 | public class Solution { |
38 报数
此题的官方地址
问题描述
报数序列是一个整数序列,按照其中的整数的顺序进行报数,得到下一个数。其前五项如下:
1 —> 1
2 —> 11
3 —> 21
4 —> 1211
5 —> 111221
省略~
1 被读作 “one 1” (“一个一”) , 即 11。
11 被读作 “two 1s” (“两个一”), 即 21。
21 被读作 “one 2”, “one 1” (”一个二” , “一个一”) , 即 1211。
给定一个正整数 n(1 ≤ n ≤ 30),输出报数序列的第 n 项。
注意:整数顺序将表示为一个字符串。
示例 1:
输入: 1
输出: “1”
示例 2:
输入: 4
输出: “1211”
问题分析
这个算法问题我缕了几遍,着实没看懂,去评论区一看同样情况的大有人在,最后看了网友的评论才理解题目的意思,2333~
题目的意思是对序列前一个数进行报数。数列第一项是1,那第二项就报第一项的有1个1,输出11。然后第三项就在第二项的基础上报数,第二项是11,第三项不就是2个1么,然后输出21。
我的解答
字典
使用Map集合将 1~30 所有的答案预先存放到Map集合,调用函数时取出返回。该方法虽然效率高、占用内存空间小,但是只适用于求解该题,我们可以换个更优雅的方法来解决。
1 | /* |
常规法
使用字典预存1的报数,在获取n的报数时,从1~n依次进行翻译,并将1~n中间的结果存入字典,方便下次直接使用。没有更深入的去研究,下面的实现执行用时有些高。
1 | /* |
官方题解
此题官方没有给出解答,我找了个优质题解来看下。
作者:jimmy00745
原文地址
来源:力扣(LeetCode)
具体思路:
- 先设置上一人为’1’
- 开始外循环
- 每次外循环先置下一人为空字符串,置待处理的字符num为上一人的第一位,置记录出现的次数为1
- 开始内循环,遍历上一人的数,如果数是和num一致,则count增加。
- 若不一致,则将count和num一同添加到next_person报的数中,同时更新num和count
- 别忘了更新next_person的最后两个数为上一个人最后一个字符以及其出现次数!
1 | class Solution: |
53 最大子序和
此题的官方地址
问题描述
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
进阶:如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
我的解答
我在尝试求解该题时,陷入了思维误区,代码实现也越来越复杂,在继续尝试一番后无奈放弃。转到评论区,看到有人说这道题是清华考研专业课算法题,能上清华的果然有实力~
精选解答
动态规划
动态规划的思路:
声明两个变量,一个变量存最终结果,一个缓存对目前状态有增益的子序列之和。
如果之前缓存的子序列之和大于零,说明其是对之后状态有增益的,加上当前状态的值并更新缓存;反之则舍弃,只取当前状态的值更新至缓存。
作者:guanpengchn
链接:原文地址
来源:力扣(LeetCode)
思路:
- 这道题用动态规划的思路并不难解决,比较难的是后文提出的用分治法求解,但由于其不是最优解法,所以先不列出来
- 动态规划的是首先对数组进行遍历,当前最大连续子序列和为 sum,结果为 ans
- 如果 sum > 0,则说明 sum 对结果有增益效果,则 sum 保留并加上当前遍历数字
- 如果 sum <= 0,则说明 sum 对结果无增益效果,需要舍弃,则 sum 直接更新为当前遍历数字
- 每次比较 sum 和 ans的大小,将最大值置为ans,遍历结束返回结果
- 时间复杂度:O(n)
1 | class Solution { |
分治法
还记得吗?分治法在前面最长公共前缀这道算法题出现过。
作者:pandawakaka
链接:原文地址
来源:力扣(LeetCode)
分治法其他题解里将的很清楚了。其实就是它的最大子序和要么在左半边,要么在右半边,要么是穿过中间,对于左右边的序列,情况也是一样,因此可以用递归处理。中间部分的则可以直接计算出来,时间复杂度应该是 O(nlogn)。
1 | class Solution: |
58 最后一个单词的长度
链接:原文地址
来源:力扣(LeetCode)
问题描述
给定一个仅包含大小写字母和空格 ‘ ‘ 的字符串,返回其最后一个单词的长度。
如果不存在最后一个单词,请返回 0 。
说明:一个单词是指由字母组成,但不包含任何空格的字符串。
示例:
输入: “Hello World”
输出: 5
我的解答
目前为止,得到的最好的解答成绩,美滋滋~。由于解该题并没有花费太多时间,所以又思考了一下其他解法:
- 将字符串中的单词裁剪出来存放到集合,获取最后一个集合元素的长度。
- 分治法,只是想到能处理该问题,并没有写代码实现。
1 | /* |
注:下面的代码实现并不适合求解该题,更适用于获取字符串中的所有单词。
1 | /* |
精选题解
作者:guanpengchn
链接:原文地址
来源:力扣(LeetCode)
看了该题解后,发现可以继续优化我的解法,我的解法是从前往后找最后一个单词,其实可以反过来从后往前找。
思路
- 标签:字符串遍历
- 从字符串末尾开始向前遍历,其中主要有两种情况
- 第一种情况,以字符串”Hello World”为例,从后向前遍历直到遍历到头或者遇到空格为止,即为最后一个单词”World”的长度5
- 第二种情况,以字符串”Hello World “为例,需要先将末尾的空格过滤掉,再进行第一种情况的操作,即认为最后一个单词为”World”,长度为5
- 所以完整过程为先从后过滤掉空格找到单词尾部,再从尾部向前遍历,找到单词头部,最后两者相减,即为单词的长度
- 时间复杂度:O(n),n为结尾空格和结尾单词总体长度
1 | class Solution { |
66 加一
链接:原文地址
来源:力扣(LeetCode)
问题描述
给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入: [1,2,3]
输出: [1,2,4]
解释: 输入数组表示数字 123。
示例 2:
输入: [4,3,2,1]
输出: [4,3,2,2]
解释: 输入数组表示数字 4321。
我的解答
类型转换求解
思路:将IntArray转换为整数,+1后再转换回IntArray进行返回。
1 | /* |
数组遍历
遍历数组求解,该想到的点都想到了,就是代码实现惨不忍睹,原因一是想到IntArray是指针变量,该题需要返回值那就不应该修改原数组的元素,原因之二是这次求解有些依赖Kotlin的语法糖了,不用的话代码可以写的更简洁一些。
1 | /* |
精选题解
作者:yhhzw
链接:原文地址
来源:力扣(LeetCode)
根据题意加一,没错就是加一这很重要,因为它是只加一的所以有可能的情况就只有两种:
- 除9之外的数字加一;
- 数字9。
加一得十进一位个位数为0加法运算如不出现进位就运算结束了且进位只会是一。
所以只需要判断有没有进位并模拟出它的进位方式,如十位数加1个位数置为0,如此循环直到判断没有再进位就退出循环返回结果。
然后还有一些特殊情况就是当出现99、999 之类的数字时,循环到最后也需要进位,出现这种情况时需要手动将它进一位。
1 | class Solution { |
由于后期改成了使用算法标签进行解答,不再根据顺序和页数进行分类,所以将下面的题移了过来。
860 柠檬水找零
LeetCode简单算法题:860~1013
闹了个乌龙,打算每篇博客50到题,从简单算法题第一道往后一道道刷的,结果不知怎的从第五页开始了。。。
so,这篇博客就先做了一道放在了这里,立个flag,看看刷到这里需要多久~
期待我尽早刷到这里吧,哈哈
问题描述
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
解答过程(2019.03.25)
这是我最开始提交的Java实现,结果提交后发现错了,梳理了几遍后依旧没有头绪。迫不得已点击了答案,发现把该问题想简单了:顾客支付的钱只有固定的5,10,20三种,只需要梳理三种支付方式可能出现的情况,就能正确解答。
1 | class Solution { |
官方解答
思路
最初,没有5美元和10美元的钞票,收到20美元的钞票后,该20美元不能用于找零。
- 顾客支付5美元钞票,得到一张5美元的钞票
- 顾客支付10美元钞票
- 有5美元钞票,找零
- 没有5美元钞票,无法找零,返回false
- 顾客支付20美元钞票
- 有5美元和10美元钞票,用一张10美元和5美元钞票找零更有利于以后找零
- 只有5美元钞票,用三张5美元进行找零
- 其他情况,无法找零。
- 只有20美元钞票
- 只有10美元钞票
- 没有钞票
1 | class Solution { |
118 杨辉三角
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
问题描述
给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
示例:
1 | 输入: 5 |
我的解答
经过之前几十道算法题的洗礼,我在解答这道题时并没有花费什么功夫,思路也很简单,明白了每行的每个元素怎么求值题就解了。元素求值有两种方式:
- 每行的第一个和最后一个元素值恒为1
- 每对相邻的元素值的和是下一行对应元素的值。
Java语言实现。
1 | class Solution { |
Kotlin语言实现,思路同上面的Java实现。
1 | /* |
官方解答
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
方法:动态规划
实现思路和我的思路一致,这里不再累述,只贴出代码实现。但还是建议看下原文链接,有动态演示,很方便理解。
虽然这一算法非常简单,但用于构造杨辉三角的迭代方法可以归类为动态规划,因为我们需要基于前一行来构造每一行。
1 | class Solution { |
169 求众数
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
问题描述
给定一个大小为n的数组,找到其中的众数。众数是指在数组中出现次数大于n/2的元素。
你可以假设数组是非空的,并且给定的数组总是存在众数。
示例 1:
输入: [3,2,3]
输出: 3
示例 2:
输入: [2,2,1,1,1,2,2]
输出: 2
我的解答
这道题正确解答很简单,解法也有很多种,但是想解的好却不容易。短时间内我也只写出了下面两种解法,虽然想到了分治法也能求解,但是没有用代码实现。建议看看下面的官方题解,一些解法真的巧妙!
哈希表
思路很简单,用一个循环遍历数组,将元素和元素出现的次数存入到哈希表,最后迭代哈希表得到众数。
1 | class Solution { |
暴力法
双重循环求解,外层循环控制元素,内层循环计算元素出现的次数,当出现满足众数条件时返回元素。
由于该解法使用双重循环,导致执行用时过高,远超出我预期。
1 | class Solution { |
官方题解
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
这里过滤了一些常规解答,只列出了比较巧妙的解法,对其他解法感兴趣的同学可以点击地址看下。
排序
所有解法中代码行数最少,只有两行:
1 | class Solution { |
思路:满足众数条件的元素,出现的次数超出了数组总长度的一半,那么在为数组排序后,数组最中间的元素肯定就是众数!
[3,2,3] 排序后:[2,3,3],最中间的元素是:3
[2,2,1,1,1,2,2] 排序后:[1,1,1,2,2,2,2],最中间的元素是:2
随机化
思路:由于一个给定的下标对应的数字很有可能是众数,我们随机挑选一个下标,检查它的值是否是众数,如果是就返回,否则继续随机挑选。
1 | class Solution { |
Boyer-Moore 投票算法
该算法的思路及其巧妙,在看完时对作者竖然起敬,然后发现这不是“开心消消乐”吗?!
思路
- 如果我们把众数记为 +1,把其他数记为 -1,将它们全部加起来,显然和大于 0,从结果本身我们可以看出众数比其他数多。
- 定义一个候选众数 candidate,再维护一个计数器 count。遇到和 candidate 相同的数字, count 加一,否则 count 减一。当 count 等于0时,忽略钱买额数字,将候选众数 candidate 改为下一个数字,计数器 count 重置为0。这样最后剩下的候选众数 candidate 就是要求的众数。
- 来看两个示例(竖线用来划分每次计数器归零的情况)。
[7, 7, 5, 7, 5, 1 | 5, 7 | 5, 5, 7, 7 | 7, 7, 7, 7]
[7, 7, 5, 7, 5, 1 | 5, 7 | 5, 5, 7, 7 | 5, 5, 5, 5]
1 | class Solution { |
448 找到所有数组中消失的数字
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
问题描述
给定一个范围在1 ≤ a[i] ≤ n(n=数组大小)的整型数组,数组中的元素一些出现了两次,另一些只出现一次。
找到所有在 [1, n] 范围之间没有出现在数组中的数字。
您能在不使用额外空间且时间复杂度为O(n)的情况下完成这个任务吗? 你可以假定返回的数组不算在额外空间内
示例:
输入:
[4,3,2,7,8,2,3,1]
输出:
[5,6]
我的解答
该题还是有一定的难度的,尤其是要求不使用额外空间且时间复杂度为O(n)的情况下完成这个任务。
- 思索来思索去,并没有想到优雅些的解决办法,所以使用暴力法进行求解,结果提交后没有通过。又审了几遍题,发现是我忽略了一点:n=数组大小,找出[1, n]范围之间没有出现在数组中的数字,惭愧的很。
- 修改后再次提交,顺利通过,但执行结果惨不忍睹。再来!
- 使用动态规划求解,执行结果有些超出预期,但代码实现可读性有些差。再来!
- 修改后的动态规划代码实现看起来就舒服了一些!
收工,看下官方题解。
暴力法
1 | /** |
修改后的暴力法
1 | /** |
动态规划
1 | /** |
优化过的动态规划
1 | /** |
精选题解
作者:haydenmiao
链接:地址
来源:力扣(LeetCode)
思路:
- 将数组元素对应为索引的位置加n
- 遍历加n后的数组,若数组元素值小于等于n,则说明数组下标值不存在,即消失的数字
1 | class Solution { |
作者没有使用Java和Kotlin语言实现该解题思路,我使用Kotlin语言进行了实现。
1 | /** |
566 重塑矩阵
作者:LeetCode
来源:力扣(LeetCode)
链接:地址
在MATLAB中,有一个非常有用的函数reshape,它可以将一个矩阵重塑为另一个大小不同的新矩阵,但保留其原始数据。
给出一个由二维数组表示的矩阵,以及两个正整数r和c,分别表示想要的重构的矩阵的行数和列数。
重构后的矩阵需要将原始矩阵的所有元素以相同的行遍历顺序填充。
如果具有给定参数的reshape操作是可行且合理的,则输出新的重塑矩阵;否则,输出原始矩阵。
示例 1:
输入:
nums = [[1,2],[3,4]]
r = 1, c = 4
输出:
[[1,2,3,4]]
解释:
行遍历nums的结果是 [1,2,3,4]。新的矩阵是 1 * 4 矩阵, 用之前的元素值一行一行填充新矩阵。
示例 2:
输入:
nums = [[1,2],[3,4]]
r = 2, c = 4
输出:
[[1,2],[3,4]]
解释:
没有办法将 2 2 矩阵转化为 2 4 矩阵。 所以输出原矩阵。
注意:
给定矩阵的宽和高范围在 [1, 100]。
给定的 r 和 c 都是正数。
我的解答
解题思路:
- 先判断原始矩阵和转换后的新矩阵的元素个数是否相等。
- 若相等,说明可以转换;若不相等,说明不能转换。
- 使用“双指针”:rowCount和colCount代表原始矩阵的行和列,依次取出原始矩阵中的元素存放到新矩阵中即可。
1 | /** |
官方题解
作者:LeetCode
链接:题解
来源:力扣(LeetCode)
看了官方题解后,发现我的解答法是“不用额外空间”,不过官方给出的题解思路很相似,复杂度上也都相同,该题并没有特别“巧妙”的解法。
使用队列 [通过]
最简单的方法是通过以行方式读取元素来提取给定矩阵的所有元素。在此实现中,我们使用队列来放置提取的元素。然后,我们可以取出以串行顺序形成的队列元素,并再次按行逐行排列所得到的所需矩阵中的元素。
如果原始矩阵中的元素数量不等于所得矩阵中的元素数量,则不可能形成所得矩阵。
1 | public class Solution { |
不用额外空间 [通过]
我们不必像在暴力方法中那样不必要地使用队列,而是可以在逐行顺序迭代给定矩阵的同时,直接将数字放在结果矩阵中。在将数字放入结果数组时,我们固定一个特定的行,并继续增加列数,直到我们到达cc指示的所需列的末尾。此时,我们通过递增来更新行索引,并将列索引重置为从0开始。因此,我们可以节省队列消耗的空间,以便存储只需要复制到新数组中的数据。
1 | public class Solution { |
除法和取模 [通过]
在上一种方法中,我们需要跟踪我们何时到达结果矩阵的列的末尾,并且需要通过每次检查当前索引来更新当前行和列号以放置提取的元素。我们可以利用数学来帮助解决,而不是在每一步都进行限制性检查。
这种方法背后的想法如下。
你知道二维数组是如何存储在主存中的(本质上是一维)吗?它仅在内部表示为一维阵列。
元素 nums[i][j]nums 数组通过使用以下形式的索引以一维数组的形式表示:$ nums [n * i + j],其中 m 是给定矩阵中的列数。
以相反的顺序查看相同的内容,同时将元素放在结果矩阵中的元素中,我们可以使用 count 变量,该变量对于遍历的每个元素都会递增,就像我们将元素放在一维中一样结果数组。
但是,要将 count 转换回列数为转换回列数为 c 的二维矩阵索引,我们可以获得 res [count / c] [count \%c] 的索引,其中 count / c 是行号和是行号和 count \%c $是列数字。因此,我们可以节省每一步所需的额外检查。
1 | public class Solution { |
661 图片平滑器
作者:LeetCode
来源:力扣(LeetCode)
链接:地址
包含整数的二维矩阵 M 表示一个图片的灰度。你需要设计一个平滑器来让每一个单元的灰度成为平均灰度 (向下舍入) ,平均灰度的计算是周围的8个单元和它本身的值求平均,如果周围的单元格不足八个,则尽可能多的利用它们。
示例 1:
输入:
[[1,1,1],
[1,0,1],
[1,1,1]]
输出:
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
解释:
对于点 (0,0), (0,2), (2,0), (2,2): 平均(3/4) = 平均(0.75) = 0
对于点 (0,1), (1,0), (1,2), (2,1): 平均(5/6) = 平均(0.83333333) = 0
对于点 (1,1): 平均(8/9) = 平均(0.88888889) = 0
注意:
- 给定矩阵中的整数范围为 [0, 255]。
- 矩阵的长和宽的范围均为 [1, 150]。
我的解答
思路:“双重嵌套”+“补位”
- 创建一个新的矩阵,双重嵌套遍历矩阵。
- 通过“补位”使原矩阵中每个单位周围有8个单位格。
- 在双重嵌套最内部计算单位的平均值,通过单元在矩阵中的坐标判断是否是“补位”单元,来计算平均值。
1 | /** |
精选题解
见我的解答,得瑟一波~
我在看了部分题解后,并没有发现特别好的解题思路,有些解法思路复杂、实现繁琐,并没有我的解法简洁,所以毛(hoz)遂(yan)自(wu)荐(chi)把自己的解法贴了出来。貌似,“矩阵”类的算法题并没有特别好的解法?
再毛(chou)遂(bu)自(yao)荐(lian)一次,我把我的题解也发布到LeetCode上了,点这里查看,欢迎点赞和交流!
941 有效的山脉数组
作者:LeetCode
来源:力扣(LeetCode)
链接:地址
给定一个整数数组 A,如果它是有效的山脉数组就返回 true,否则返回 false。
让我们回顾一下,如果 A 满足下述条件,那么它是一个山脉数组:
- A.length >= 3
在 0 < i < A.length - 1 条件下,存在 i 使得:
- A[0] < A[1] < … A[i-1] < A[i]
- A[i] > A[i+1] > … > A[B.length - 1]
示例 1:
输入:[2,1]
输出:false
示例 2:
输入:[3,5,5]
输出:false
示例 3:
输入:[0,3,2,1]
输出:true
提示:
- 0 <= A.length <= 10000
- 0 <= A[i] <= 10000
我的解答
思路:只需要一次循环
- 要解答该题,首先要找到”山脉”最高点maxElIndex。
- 在找到maxElIndex前,后面的元素小于等于前面的元素,说明不是有效的”山脉数组”。
- 在找到maxElIndex后,后面的元素大于等于前面的元素,说明不是有效的”山脉数组”。
- 排除上面两种情况后,最后再检查一下找到的最高点不能是第一个和最后一个元素。
1 | /** |
官方题解
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
线性扫描
我们从数组的最左侧开始扫描,直到找到第一个不满足 A[i] < A[i + 1] 的 i,那么 i 就是这个数组的最高点。如果 i = 0 或者不存在这样的 i(即整个数组都是单调递增的),那么就返回 false。否则从 i 开始继续扫描,判断接下来的的位置 j 是否都满足 A[j] > A[j + 1],若都满足就返回 true,否则返回 false。
1 | class Solution { |
509 斐波那契数
作者:LeetCode
来源:力扣(LeetCode)
链接:地址
很著名的一道算法,以至于我在没研究算法之前就听说过它的名头。
问题描述
斐波那契数,通常用F(n)表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
给定 N,计算 F(N)。
示例 1:
输入:2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1.
示例 2:
输入:3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2.
示例 3:
输入:4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3.
提示:
0 ≤ N ≤ 30
我的解答
递归+缓存
效率稍高,最多会递归计算 N-2 次。使用map缓存数据,多次调用后,会大大地减少递归次数,比较适合应用于实际项目开发。
1 | class Solution { |
递归
代码最少的一个解法,缺点是效率低,因为会递归计算 N-2+N-1-2 次。
1 | class Solution { |
11 盛最多水的容器
作者:LeetCode
来源:力扣(LeetCode)
链接:地址
问题描述
给定 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。
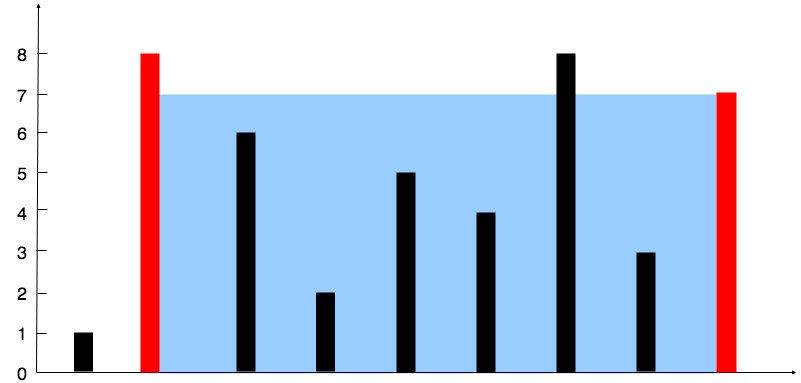
图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
示例:
输入: [1,8,6,2,5,4,8,3,7]
输出: 49
我的解答
看到这道题后,我经过一番思考,想出了两种方法:暴力法、动态规划(不推荐)。
暴力法
1 | /** |
动态规划(不推荐)
思路:
- 形成容器需有两条垂直线,计算盛水量,需要两个因素:两条垂直线在X轴的距离 * 较短的一条垂直线长度。
- 那么就可以使用其中任意一个因素,从大到小依次计算容器,这样可以减少遍历次数。
注意:
上面的思路初看起来没有问题,但题目要求求解最大容器,那么就没有办法知道根据计算因素从大到小计算的容器大小是否是最大容器,虽然最终还是能求解,但执行用时比暴力求解还高。代码实现比较复杂,这里就不贴出来了献丑了,惭愧~
官方题解
作者:LeetCode
链接:地址
来源:力扣(LeetCode)
暴力法
在这种情况下,我们将简单地考虑每对可能出现的线段组合并找出这些情况之下的最大面积。
1 | public class Solution { |
复杂度分析:
- 时间复杂度:O(n^2),计算所有 frac{n(n-1)}{2} 种高度组合的面积。
- 空间复杂度:O(1),使用恒定的额外空间。
双指针法
这种方法背后的思路在于,两线段之间形成的区域总是会受到其中较短那条长度的限制。此外,两线段距离越远,得到的面积就越大。
我们在由线段长度构成的数组中使用两个指针,一个放在开始,一个置于末尾。 此外,我们会使用变量maxarea 来持续存储到目前为止所获得的最大面积。 在每一步中,我们会找出指针所指向的两条线段形成的区域,更新maxarea,并将指向较短线段的指针向较长线段那端移动一步。
此解有幻灯片进行动态的展示,可以更好的理解该算法,如果文字描述理解困难,建议看下幻灯片。
1 | public class Solution { |
复杂度分析:
- 时间复杂度:O(n),一次扫描。
- 空间复杂度:O(1),使用恒定的空间。
18 四数之和
作者:LeetCode
来源:力扣(LeetCode)
链接:地址
问题描述
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
答案中不可以包含重复的四元组。
示例:
给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。
满足要求的四元组集合为:
[
[-1, 0, 0, 1],
[-2, -1, 1, 2],
[-2, 0, 0, 2]
]
我的解答
预先告知,我是没能求解,23333~。第一时间想到的暴力法超时,然后想到了双指针法,但时间不充裕就没尝试代码实现,直接看了别人的解答,学到了“拍平”的思路。中等难度的算法果然又开阔了解题思路~。
暴力法(超时,不可取)
修改了三次答案,最后一次的答案能求出正确结果,但是超出了时间限制。很遗憾,暴力法并不能用于求解该题。
1 | class Solution { |
精选题解
作者:jerry4free
链接:地址
来源:力扣(LeetCode)
双指针法
模拟两数之和,采用双指针,时间复杂度是O(N^3)。防止重复需要判断。
1 | class Solution { |
哈希表
如何才能O(N^2)呢?需要将两层循环拍平,拍成一层循环,那么就可以达到O(N^2).
可以将2层的数字预先计算求和,存储到哈希表里方便快速查找。防止重复可以用集合
1 | class Solution { |